踩坑实录之Project 0:C++ 实现字典树
本文最后更新于:2023年7月29日 凌晨
1 介绍
Project 0, 也就是C++ Primer, 是 CMU15-445 2022-Fall 课程的入门项目,重点考察 Cpp11 (及以上版本) 的基础语法, 包括与面向对象、泛型编程相关的基本特性。这门课程的所有项目需要在 Bustub (一个专门为课程教学设计的 DBMS,也可见课程之用心…)中使用 Cpp 进行编写。
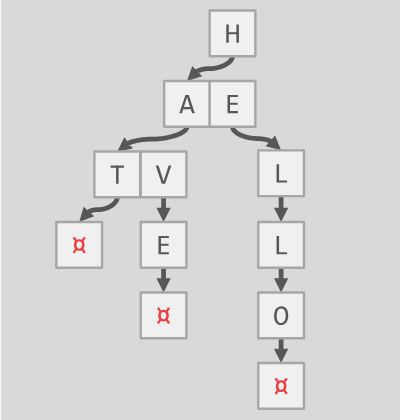
该项目要求为 Bustub 实现一个支持键值对存储的字典树(Trie树,如下图所示)。这里博主回忆起了之前在《数据结构与算法分析:C++语言描述》(第四版) 中看到的关于后缀树和后缀数组 (Suffix Array) 的内容。这两种数据结构 (前缀树和后缀树) 感觉非常相似,都可以支持在字符串中快速查找给定的模式。那本书中给出了后缀数组和最长公共前缀数组 (Longest Common Prefix, 二者合并可以唯一确定后缀树) 的一种 O(N) 实现,非常烧脑。博主在做这个项目之前也重温了一下这部分的内容,以为会有共同之处。幸运的是,项目中 Trie 树的实现基于 STL 提供的 HashMap, 还是比较容易理解的。
值得注意的是,目前该数据库已经更新到支持 2023-Spring 的教学要求, 与 2022-Fall 的课程要求并不完全相同。 庆幸的是,课程团队提供了一个 2022-Fall 的发布版。如果需要完成 2022-Fall 的项目,git clone 时必须指定 branch (博主之前对着 2023-Spring 的代码和 2022-Fall 的项目说明,懵逼了半天…):
1 | |
Git 常用指令
博主在开始项目之前,对 git 的常用指令以及维护 github 仓库也完全不熟练,踩了不少坑。简单来说,git 的主要功能是实现软件版本控制,同时辅助协同开发。git 指令提供了非常多的选项,简单使用的话只需要知道其中几个即可:
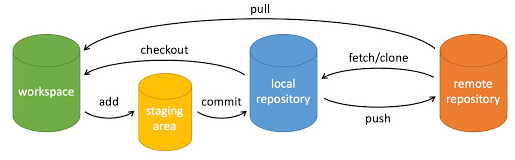
git init [<repo-name>]
初始化 git 仓库。该命令默认当前路径下创建 .git 文件,其中包含了版本控制所需的元数据;可以提供文件夹名称,在指定文件夹中建立 git 仓库; 同时,该指令默认创建 main 分支。git add .
将所有改动的文件添加到暂缓区域(staging),并跟踪其变化;可以具体指定文件名。git commit -m 'descreption'
将暂缓区内容提交到本地仓库。git push <remote-repo> <local-branch>:<remote-branch>
将本地分支推送到远程仓库并合并; 若本地分支与远程分支名相同,可以不写冒号后的内容。git pull <remote-repo> <remote-branch>: <local-branch>
拉取远程主机的 remote-branch 分支,合并到本地的 local-branch 分支;若与当前分支合并,可以省略 local-branch。
以上四条指令, 加上 git clone 可以满足基本的本地代码开发要求。涉及远程仓库的指令常常对网络环境有要求,使用 SSH 进行连接可以避免一些问题(添加 SSH 密钥参考之前的 Blog)。以下再补充一些其它常用的指令:
git remote add <alias-name> <remote-repo>
为远程主机添加一个别名,可以方便推送和拉取;git remote rm <alias-name>用于删除别名,git remote rename <old> <new>用于重命名别名。git status
查看当前仓库状态,显示有变更的文件。git branch [<new-branch-name>]
列出当前仓库的所有分支;提供分支名时,将创建该名称的新分支。git checkout <branch-name>
切换至给定名称的分支;该命令会将当前工作区恢复到创建该分支时候的模样。
这些指令基本满足了博主当前开发的所有需求,让我也对 git 的工作方式有了初步的了解,更详细的说明可以参考这里。
2 环境搭建
工欲善其事,必先利其器。毫无疑问,一个高效、优雅的编码环境,将带来事半功倍的效果。
2.1 项目编译
作者推荐在 Ubuntu 20.04 以上的版本或者 macOS 中编译、开发、测试 Bustub, 而其它开发环境不能保证正常工作。博主本人的开发机是 Windows 10, 测试机是 Ubuntu 18.04。博主一开始试图直接在测试机中安装项目所需的开发工具,意识到确实很难完整安装所有工具的推荐版本,也无法生成完整的项目文件。主要原因是,项目要求用 clang-12 进行编译,而 Ubuntu 18.04 最高只支持到 clang-6。
为了减少踩坑,决定采用作者提供的 Docker 容器对文件进行编译。编译过程很顺利,所有的编译工具都能被顺利安装。值得注意的是,为了方便 Debug, 作者建议在容器中安装 GDB 调试工具,同时任何时候 cmake 都指定为 Debug 模式,即
1 | |
这里有一个小坑,指定 Debug 模式的时候,会报 warning,提示CMake 并没有使用推荐的编译器。 这里可以修改 CMakeLists.txt, 手动指明使用的编译器:
1 | |
2.2 VSCode 远程开发
由于测试机并没有提供 GUI,直接将 Vim 配置成 C++ 的开发环境对博主来说难度颇大,使用也不顺手,于时考虑在本地开发机中利用 VSCode 进行远程开发。值得注意的是,这里的远程主机是运行中的 docker 容器。
为了在外部能访问容器, 首先在创建、运行容器时,需要指定端口映射:
1 | |
其中 -t 为容器分配伪终端;-i让容器的标准输入保持打开;-p 指定端口映射,这里将本地主机的 10008 端口映射到容器的 10008 端口; -v 将本地文件挂载到容器的指定文件目录下, 这里是在 bustub 根目录下运行的 docker run 指令; 后续再指定运行的 bustub 镜像 (通过 docker build 指令建立) 和需要运行的指令(bash 进入容器的 bash 命令行)。
然后,在Docker 容器中安装 SSH 所需的依赖:
1 | |
配置容器中的 /etc/ssh/sshd_config 文件, 开放指定的 10008 端口 (如果没有该文件,则表明 SSH 服务所需的依赖没有被正确安装):
1 | |
重启 docker 的 SSH 服务:
1 | |
尝试在本地连接运行中的 docker 容器:
1 | |
如果能成功进入该容器,则表明配置正确。接下来需要在 VSCode 中安装远程开发套件 Remote Development。 安装完成后,即可连接远程主机中的容器。如果远程主机配置了免密登录,则需要将私钥保存到本地用户路径下的 .ssh 文件中。顺利连接的情况下,VSCode 会自动在容器中安装一部分依赖, 而我们也可以在本地对开发环境进行一些个性化设置。
这里推荐在 VSCode 中配置 clang-format 插件, 并在 setting.json 中开启 formatOnSave 功能, 以提高编码过程中的代码可读性。当然,项目作者本身提供了 formatting 和代码逻辑/风格的检查工具,在需要进行其它修改时, 也可以在 json 文件中很方便的关闭 formatOnSave 功能。
OK, 环境配置完毕,接下来,就可以开始快乐的 Coding 了~
3 项目开发过程
课程团队提供了关于该项目的非常详细的说明。简单来说,我们只需要在在 /src/include/primer/p0_trie.h 中完成 TrieNode 类, TrieNodeWithValue 类和 Trie 类的接口实现。
3.1 关于 unique_ptr 的使用
TrieNode 类提供单一节点的操作接口。由于使用了 STL 的 unordered_map 来管理与子节点的连接,因此实现还是相对简单的。 其中最大的坑在于处理 unique_ptr 的使用问题。
unique_ptr 是一种智能指针类。C++ 中所有智能指针的设计目标都是通过类析构函数的自动调用机制,来帮助内存管理, 使用时都应该遵循 RAII(Resource Acquision Is Initialization) 的原则,且一定要避免和普通指针混合使用。 其中 unique_ptr 是为了防止多个指针指向同一个对象时,对象删除后出现空悬指针的问题。除了一般化的使用原则外,该智能指针不允许拷贝 (一个例外是允许函数返回unique_ptr, 此时会执行特殊的复制) 和赋值 (对应的拷贝构造和拷贝赋值都被声明为 =delete), 以保证任何时刻都只有一个 unique_ptr 指向给定对象。该智能指针仅支持所有权的转移,即利用 std::move() 将对象的所有权从一个 unique_ptr 转移到另一个 unique_ptr。 除了重载了 -> 和 * 运算符外,该智能指针还支持以下常用接口:
get(): 返回对象的普通指针, 主要用于匹配函数形参;release(): 放弃对象的所有权,将该智能指针置为空;reset([ptr]): 释放 unique_ptr 所管理的资源, 并置空;或将其指向 ptr;
此外,在 C++14 及以后的版本中,还提供了 make_unique 用于构造unique_ptr。这也是后面利用 clang-tidy 进行检查时所建议的做法。
TrieNode 类的移动构造函数
由于 unique_ptr 的种种限制,资源转移时需要格外小心。博主踩的第一个坑是 TrieNode 类的移动构造函数。 在这里,需要将 TrieNode 类中的 children_ 私有成员移动到新对象中。
博主原本认为, 可以直接将 other_trie_node.children_ 传递给 unordered_map<char, std::unique_ptr<TrieNode>> 的构造函数, 编译器能够通过模板产生正确的移动构造函数。 然而事与愿违, 此时调用的仍然是复制构造函数。由于 unique_ptr 不支持复制构造, unordered_map<char, std::unique_ptr<TrieNode>> 的复制构造函数也被声明为 =delete,导致编译失败。
这里应该涉及到引用参数的模板匹配机制 (这部分个人感觉很复杂)。之所以调用复制构造函数,博主认为是直接使用参数名时,传递的依然是左值表达式 (参考《C++ Primer》(第5版) 613页)。这里需要传递右值表达式,最直接的解决办法是使用 std::move();稍微复杂一点的是使用转发, 即:
1 | |
值得注意的是, deceltype()用于右值时得到原本的类型。 另外,在移动构造函数体内进行 swap 也是一种可行的方法, 因为 children_ 应该默认是空的:
1 | |
另一个涉及到相似问题的地方是 TrieNode 类中的插入操作。由于需要在 children_ 中建立新的不存在的 key, 推荐使用 unordered_map 的 insert 方法 (使用 [] 的方式,会增加一次对 unique_ptr 对象默认构造的调用,参考《Effective STL》条款24)。 如果使用 insert 则难以避免调用 make_pair 来构造 pair 对象,此时会再次面对 unique_ptr 对象的传递问题。
总之,任何时候都要避免对 unique_ptr 以及包含 unique_ptr 的类的复制和赋值操作。
访问 unique_ptr 所管理的对象
Unique_ptr 对资源所有权的严格限制带来了一个很重要的问题——不能直接通过对象的指针去访问对象了。因为这种方式混用了普通指针和智能指针,破坏了智能指针的设计初衷; 而使用其它智能指针去引用 unique_ptr 所管理的资源也是不好的习惯(参考《C++ Primer》(第5版)417页)。
项目作者使用 unique_ptr<T>* 来访问 unqiue_ptr 所管理的对象,有效规避了上面提到的两个问题。这是一种值得借鉴的做法(暂时没有考证是不是标准做法)。
3.2 Trie 中实现 Insert
字典树的插入逻辑是比较清晰的,作者也给出了各种情况下插入操作的细节。其中有一点很值得注意。当遍历插入的字符串到尾字符时,当前节点并不是终止节点,此时需要进行将 TrieNode 类转化为 TrieNodeWithValue 类。
博主一开始使用 TrieNodeWithValue 类构造函数的 key-value 版本构造新的对象,然后替换原来的 TrieNode 类。 结果也能通过 starter_trie_test 的测试。 后来自己再补充了一些随机字符串的插入和删除,却总是出现神秘 Fail。通过打印日志,博主发现插入都是成功的,但有的查询和删除会出现失败。这意味着插入操作虽然返回了 true, 但实际上改变了插入的内容。
经过一番检查后,发现原因就在于 TrieNodeWithValue 类的构造方式。 如果构造新的对象去替换原来的 TrieNode 节点,会丢失该节点所有子节点的连接。因此,必须从原来的 TrieNode 对象构造 TrieNodeWithValue 对象。
3.3 基类指针访问派生类对象的成员
Trie 类的 GetValue 接口需要访问 TrieNodeWithValue 类的 Value_ 成员。 这里涉及到需要用基类指针访问派生类对象成员的问题。博主其实首先想到的是考虑将 GetValue 声明为 virtual 函数(在基类中添加一个空函数版本),但是作者显然没有这样考虑。有点意外,作者要求使用 dynamic_cast。
运行期类型识别 (Runtime Type Identification, RTTI)在 Google 开源项目风格指南 中是不推荐的做法,意味着存在设计问题 (建议是使用虚函数或者访问者模式来替换 RTTI)。博主本人在这方面有些过于教条了,后来发现 dynamic_cast 仍然是一个相当有用的工具。 尤其是在基类指针无法被转换时,会返回 nullptr,提供了安全保证 (但是一定要避免滥用)。这里也算是弥补了知识盲区。
3.4 并发控制
并发控制对博主来讲是完全陌生的领域。只是在学习过程中,了解过大概的思路。不过完成 Project 0 也确实不需要其它更复杂的手段,只需要简单地在进入读/写函数时上锁,离开前解锁就可以了。
有些意外的是,博主以为项目设计的 ReaderWriterLatch 也应该支持 RAII, 结果并非如此。总的来说,对于并发控制这一部分,还需要更深入的学习。
3.5 Debug 过程
项目开发过程中主要使用 GDB 进行调试, 基本能解决大部分代码逻辑的问题,包括无意识的混淆了父节点和子节点,忘记 while-loop 中的变量更新等各种迷之错误。更隐晦的逻辑错误是通过编写测试案例和打日志来解决的。不得不承认,测试和日志记录也是技术活。
项目所使用的 GTest 框架再次触及博主只是的盲区…
值得注意的是,由于整个项目大量使用智能指针,博主在整个调试过程中都没有发现有内存管理方面的问题。很意外也很庆幸,可以说以鲜活生动的实例,向博主本人充分证实了使用智能指针进行资源管理的有效性和安全性。
3.6 格式修改
课程团队对项目的代码规范有相当严格的要求,并提供了静态代码分析工具。基本的排版规范是参考 Google 的风格指南,通过 clang-format 进行自动排版。 这也是博主开发环境的默认选项。
同时,还提供了 clang-tidy 进行其它检查。给出了几条很有意思的建议:
- if-else 逻辑冗余: 避免在 return 后接 else
博主一开始在很多需要控制流中止的地方,选择立刻 return。经验上讲,博主认为这样可以避免一些不必要的问题,比如流程没有完全退出。因此,导致很多 else 出现在了 return 之后。不过确实,这个问题基本可以通过删除不必要的 else 语句进行调整,极大减少了不必要的逻辑分支。 - 另一种 if-else 逻辑冗余的形式: 在 if 语句块中只返回 bool 值确实。这完全可以去掉 if, 让代码更精简。
- 要求所有的 if-else 语句中都加大括号
也无可厚非吧,比较看个人喜好。 - 未使用 make_unique
这是 C++14 的新特性,之前确实忽略了。推荐使用 make_unique 应该有深层次的原因。
4 总结
第一个项目从开始编码到最后提交通过大概花了 1.5 天,加上环境配置的话应该有 2 天了。 总的来说,虽然是该课程最简单的项目,但也令我收获满满。首先,项目本身的代码质量很高,完成项目本身也是在吸收优秀的设计经验。其次,完成项目需要利用各种工具,除了必要的编译工具,还需要掌握测试工具,尤其是使用 GDB 进行调试和利用 GTest 进行单元测试(不过博主本身并没有在命令行中进行 GDB 调试,而是配置到了 VSCode 中)。最值得称道的是,项目的反馈感相当的足。虽然 Project 0,只要求实现很小的部分,但依然能让整个项目成功编译且产生输出;而且也向非 CMU 的学生开放了 Gradescope 评分,能进一步帮助检查代码 bug。再次为课程团队点赞!!!
另外,博主本人其实对这种大中型 (maybe?) 项目的编译过程也很感兴趣,尤其是如何组织源码文件和编写对应的 CMakeList, 毕竟为一个很小的项目编写 CMakeList 对博主来讲都有不小的挑战。 总的来说,还有很多地方需要学习。希望自己能坚持下去。